

Microsoft Cloth is an end-to-end, software-as-a-service (SaaS) platform for information analytics. It’s constructed round a data lake known as OneLake, and brings collectively new and current elements from Microsoft Energy BI, Azure Synapse, and Azure Information Manufacturing unit right into a single built-in surroundings.
Microsoft Cloth encompasses information motion, information storage, information engineering, information integration, information science, real-time analytics, and enterprise intelligence, together with information safety, governance, and compliance. In some ways, Cloth is Microsoft’s reply to Google Cloud Dataplex. As of this writing, Cloth is in preview.
Microsoft Cloth is focused at, properly, everybody: directors, builders, information engineers, information scientists, information analysts, enterprise analysts, and managers. At present, Microsoft Cloth is enabled by default for all Energy BI tenants.
Microsoft Cloth Information Engineering combines Apache Spark with Information Manufacturing unit, permitting notebooks and Spark jobs to be scheduled and orchestrated. Cloth Information Manufacturing unit combines Energy Question with the size and energy of Azure Information Manufacturing unit, and helps over 200 information connectors. Cloth Information Science integrates with Azure Machine Learning, which permits experiment monitoring and mannequin registry. Cloth Actual-Time Analytics consists of an occasion stream, a KQL (Kusto Query Language) database, and a KQL queryset to run queries, view question outcomes, and customise question outcomes on information. If KQL is new to you, welcome to the membership.
 IDG
IDGMicrosoft Cloth house display screen. Word the hyperlinks to Energy BI, Information Manufacturing unit, Information Activator, Synapse Information Engineering, Synapse Information Science, Synapse Information Warehouse, and Synapse Actual-Time Analytics.
OneLake
OneLake is a unified, logical information lake in your entire group; each tenant has one and just one information lake. OneLake is designed to be the one place for all of your analytics information, a lot in the identical approach as Microsoft needs you to make use of OneDrive for all of your information. To simplify utilizing OneLake out of your desktop, you possibly can set up OneLake file explorer for Home windows.
OneLake is constructed on Azure Information Lake Storage (ADLS) Gen2 and might help any sort of file. Nonetheless, all Cloth information elements, reminiscent of information warehouses and information lakehouses, retailer their information routinely in OneLake in Delta format (primarily based on Apache Parquet), which can be the storage format utilized by Azure Databricks. It doesn’t matter whether or not the info was generated by Spark or SQL, it nonetheless goes right into a single information lake in Delta format.
Making a OneLake information lakehouse is pretty easy: Swap to the Information Engineering view, create and identify a brand new lakehouse, and add some CSV information to the file portion of the info lake.
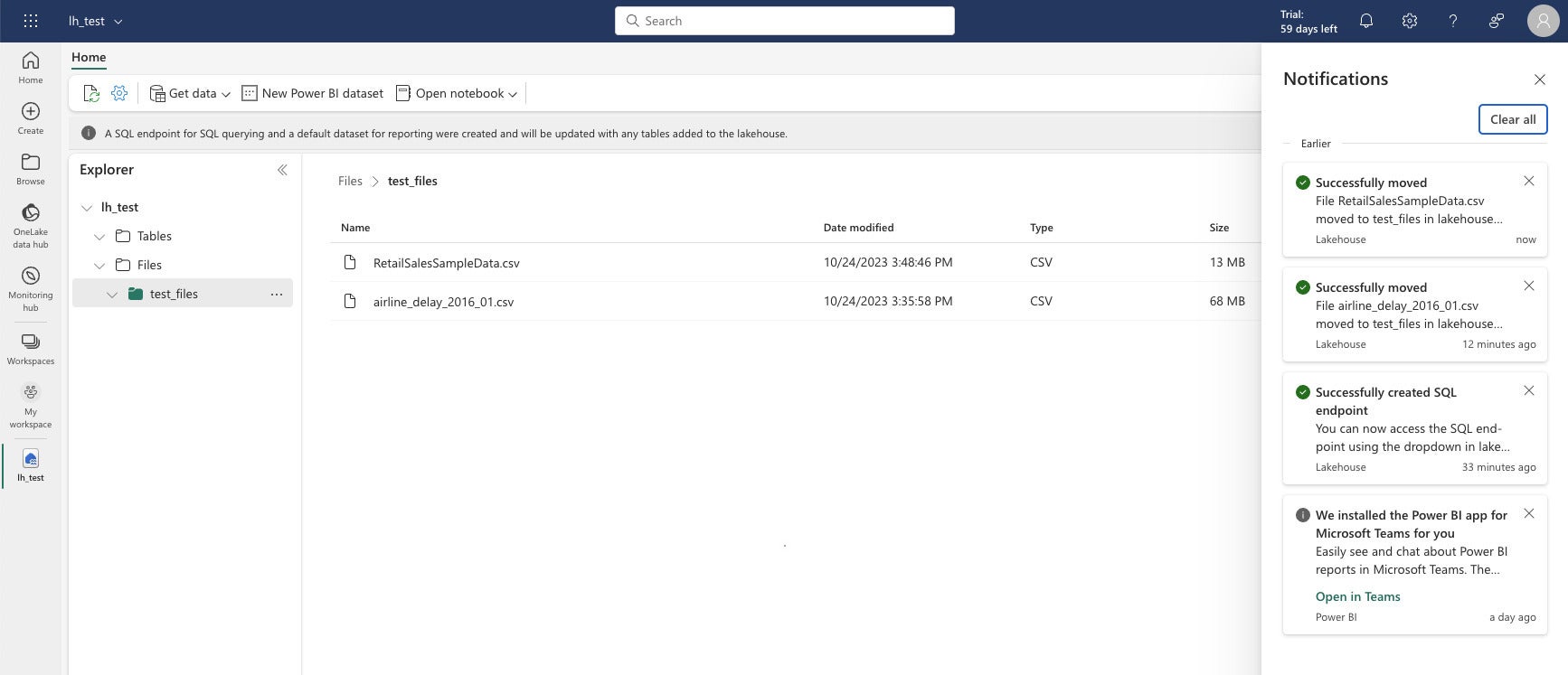 IDG
IDGWithin the information engineering view of Microsoft Cloth, you possibly can see your information and tables. Tables are in Delta Parquet format. When you choose a file, you get a three-dot menu for performing operations on that file, for instance loading it right into a desk.
Getting from there to having tables within the lakehouse can (at the moment) be extra work than you may count on. You’ll assume that the Load to Tables pop-up menu merchandise would do the job, but it surely failed for my preliminary exams. I finally found, with assist from Microsoft Help, that the Load to Tables perform doesn’t (as of this writing) know the best way to deal with column titles with embedded areas. Ouch. All of the competing lakehouses deal with that and not using a hitch, however Cloth is nonetheless in preview. I’m assured that this functionality can be added within the launched product.
I did get that conversion to work with cleaned-up CSV information. I used to be additionally in a position to run a Spark SQL question in a pocket book in opposition to a brand new desk.
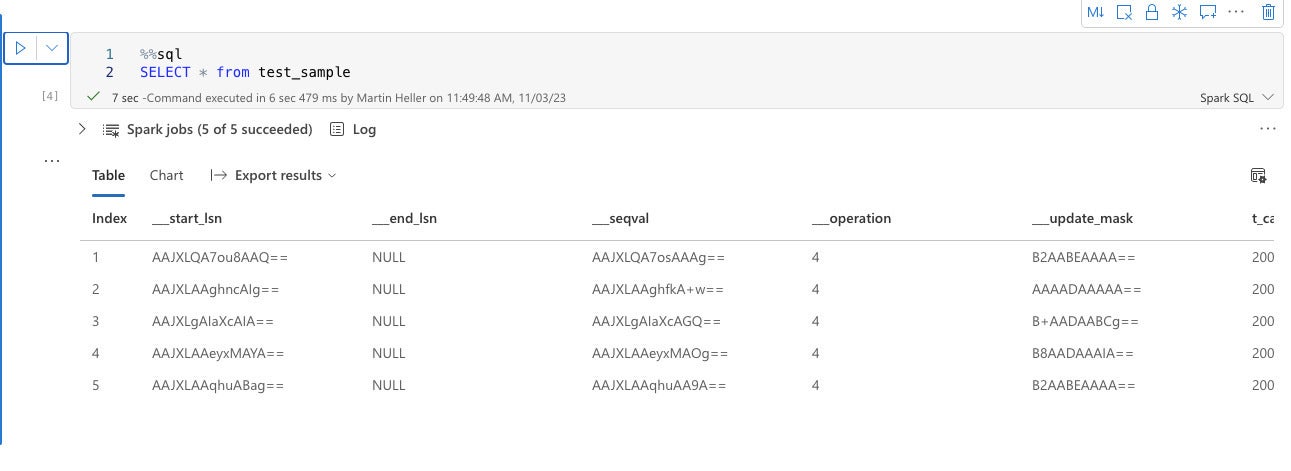 IDG
IDGCloth notebooks help each Python and SQL. Right here we’re utilizing Spark SQL to show the contents of a OneLake lakehouse desk.
Spark isn’t the one approach to run SQL queries in opposition to the lakehouse tables. You may entry any Delta-format desk on OneLake by way of a SQL endpoint, which is created routinely whenever you deploy the lakehouse. A SQL endpoint references the identical bodily copy of the Delta desk on OneLake and affords a T-SQL expertise. It’s principally utilizing Azure SQL slightly than Spark SQL.
As you’ll see later, OneLake can host Synapse Information Warehouses in addition to lakehouses. Information warehouses are greatest for customers with T-SQL abilities, though Spark customers also can learn information in warehouses. You may create shortcuts in OneLake in order that lakehouses and information warehouses can entry tables with out duplicating information.
Energy BI
Energy BI has been expanded to have the ability to work with OneLake lakehouse (Delta) tables. As all the time, Energy BI can carry out fundamental enterprise intelligence information evaluation and report technology, and combine with Microsoft 365.
 IDG
IDGA Energy BI report inside Microsoft Cloth. Just about all of the essential options of Energy BI have been carried over into Cloth.
Information Manufacturing unit
Information Manufacturing unit in Microsoft Cloth combines citizen information integration and professional information integration capabilities. It connects to some 100 relational and non-relational databases, lakehouses, information warehouses, and generic interfaces. You may import information with dataflows, which permit large-scale information transformations with some 300 transformations, use the Energy Question editor, and apply Energy Question’s Information Extraction By Instance.
I attempted a dataflow that imported and remodeled two tables from the Northwind dataset. I used to be impressed with the capabilities till the ultimate publishing step failed. OK, it’s in preview.
You can too use information pipelines to create information orchestration workflows that convey collectively duties like information extraction, loading into most popular information shops, pocket book execution, and SQL script execution. I efficiently imported two pattern datasets, Public Holidays and NY Taxi rides, and saved them into information lakes. I didn’t check the potential to replace the pipeline periodically.
If you must load on-premises information into OneLake, you’ll finally be capable to create an on-premises information gateway and join that to a dataflow. As a brief workaround, you possibly can copy your on-prem information to the cloud and cargo it from there.
Information Activator
In keeping with Microsoft, Information Activator is a no-code expertise in Microsoft Cloth for routinely taking actions when patterns or situations are detected in altering information. It displays information in Energy BI reviews and Eventstreams objects, for when the info hits sure thresholds or matches different patterns. It then routinely takes applicable motion reminiscent of alerting customers or kicking off Energy Automate workflows.
Typical use instances for Information Activator embody operating advertisements when same-store gross sales decline, alerting retailer managers to maneuver meals from failing grocery retailer freezers earlier than it spoils, and alerting account groups when prospects fall into arrears, with custom-made time or worth limits per buyer.
Information Engineering
Most of what I mentioned within the OneLake part above really falls beneath information engineering. Information Engineering in Microsoft Cloth consists of the lakehouse, Apache Spark job definitions, notebooks (in Python, R, Scala, and SQL), and information pipelines (mentioned within the Information Manufacturing unit part above).
Information Science
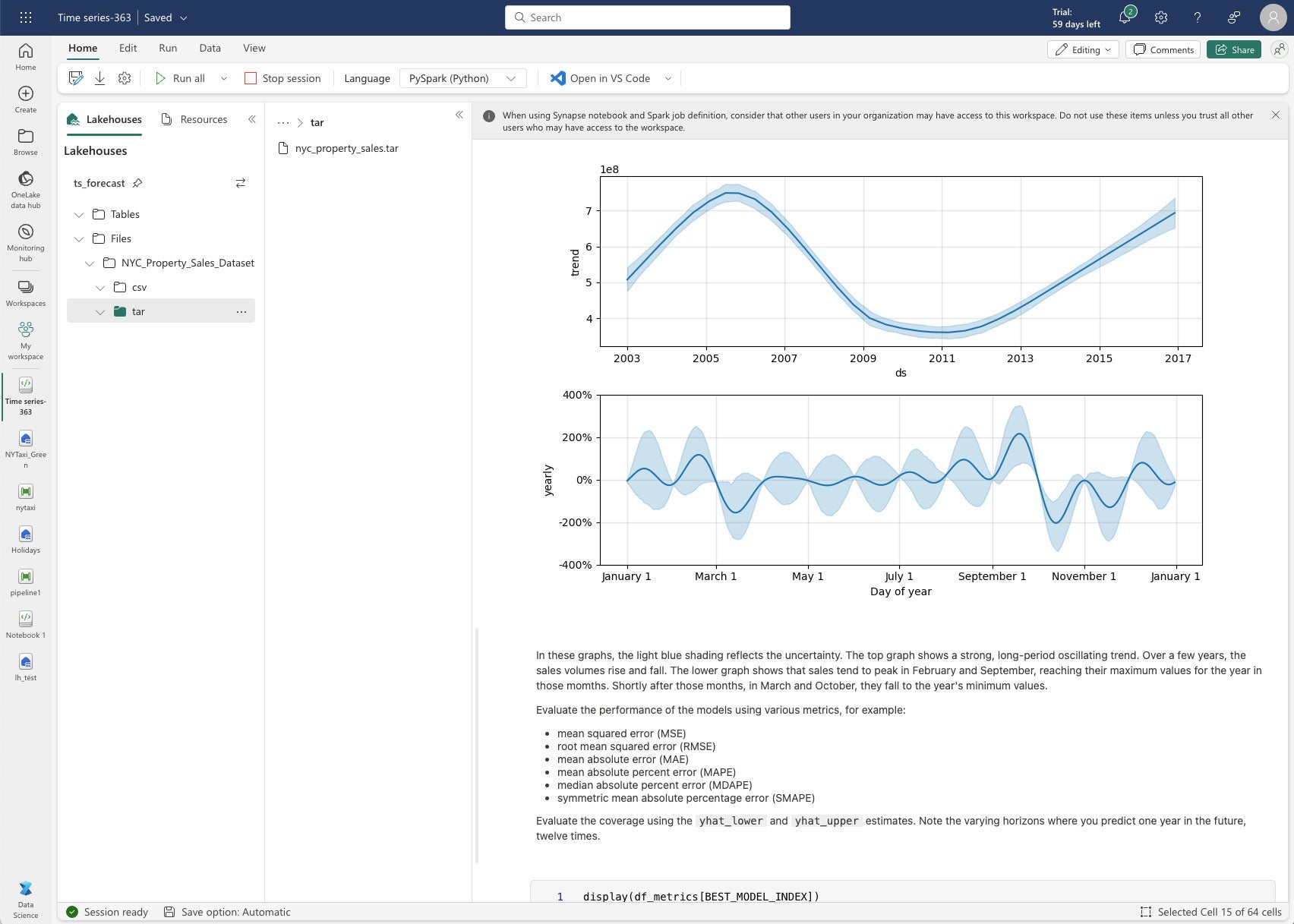
Information Science in Microsoft Cloth consists of machine studying fashions, experiments, and notebooks. It has about half a dozen pattern notebooks. I selected to run the time sequence forecasting mannequin pattern, which makes use of Python, the Prophet library (from Fb), MLflow, and the Cloth Autologging function. The time sequence forecasting pattern makes use of the NYC Property Sales data dataset, which you obtain after which add to an information lakehouse.
Prophet makes use of a conventional seasonality mannequin for time sequence prediction, a refreshing departure from the development in direction of more and more difficult machine studying and deep studying fashions. The full run time for the becoming and predictions was 147 seconds, not fairly three minutes.
 IDG
IDGPrediction of property gross sales after becoming NYC property gross sales information to a Prophet seasonality mannequin.
Information Warehouse
Information Warehouse in Microsoft Cloth goals to converge the worlds of the data lakes and data warehouses. It’s not the identical because the SQL Endpoint of the lakehouse: The SQL Endpoint is a read-only warehouse that’s routinely generated upon creation from a lakehouse in Microsoft Cloth, whereas the Information Warehouse is a “conventional” information warehouse, which means it helps the complete transactional T-SQL capabilities like every enterprise information warehouse.
Versus the SQL Endpoint, the place tables and information are routinely created, Information Warehouse places you absolutely accountable for creating tables and loading, remodeling, and querying your information within the information warehouse utilizing both the Microsoft Cloth portal or T-SQL instructions.
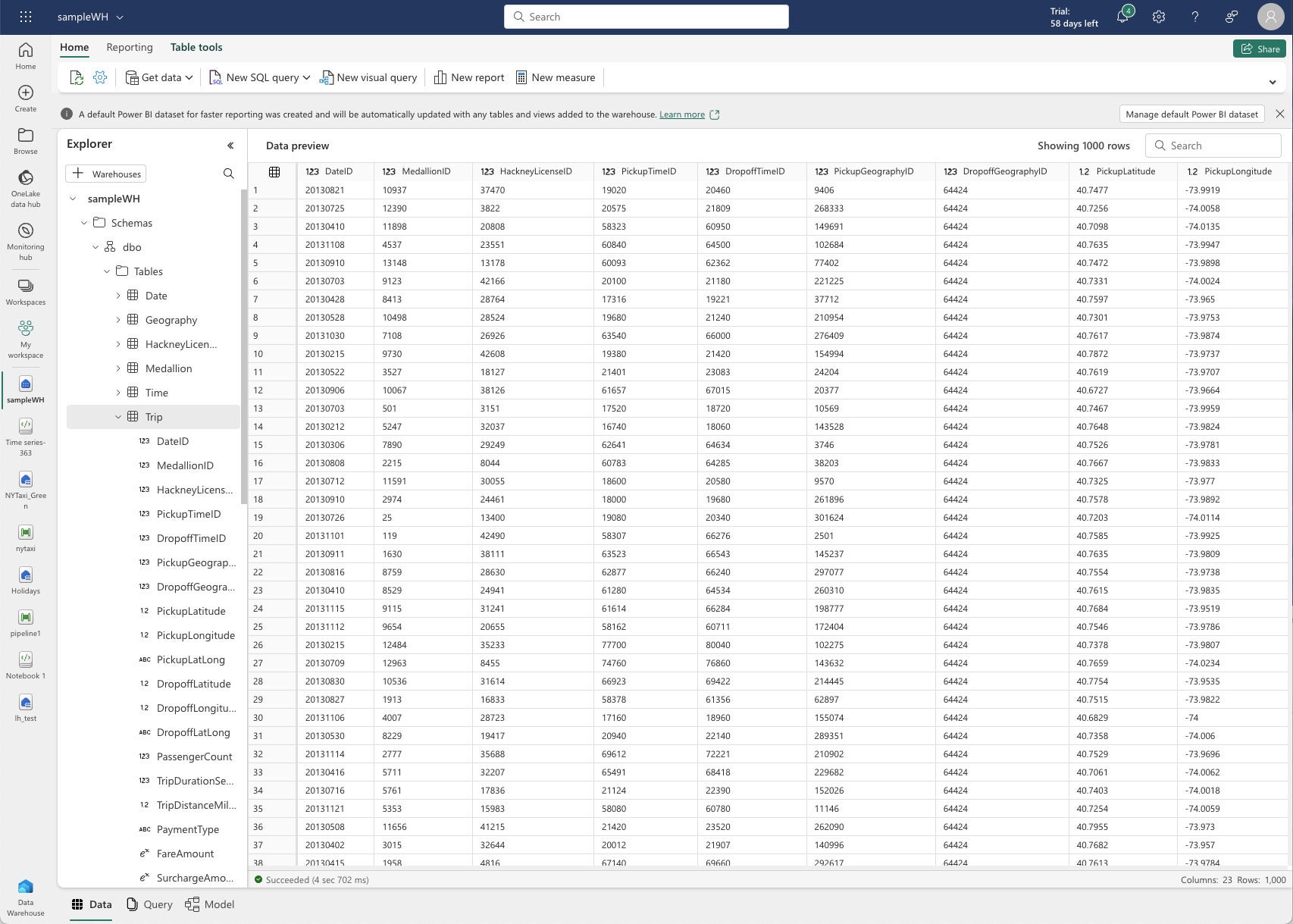
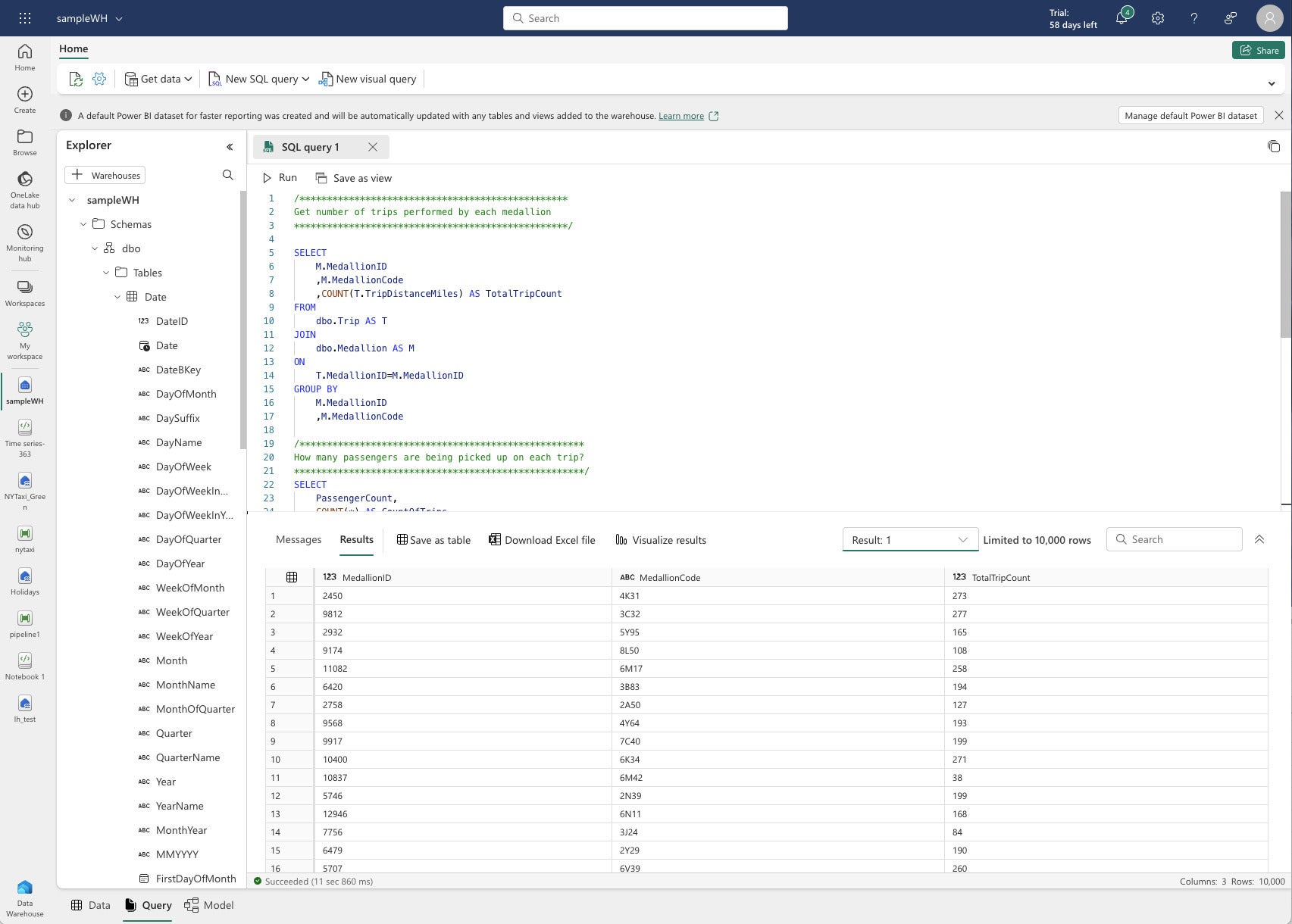
I created a brand new warehouse and loaded it with Microsoft-provided pattern information. That seems to be one other taxi journey dataset (from a unique 12 months), however this time factored into warehouse tables. Microsoft additionally supplies some pattern SQL scripts.
 IDG
IDGCloth Information Warehouse information preview for one desk. Word the messages in regards to the routinely created Energy BI dataset on the high.
 IDG
IDGCloth Information Warehouse mannequin view.
 IDG
IDGCloth Information Warehouse question view. Microsoft provided the SQL script as a part of the pattern.
Actual-Time Analytics
Actual-Time Analytics in Microsoft Cloth is carefully associated to Azure Information Explorer, so carefully that the documentation hyperlinks for Actual-Time Analytics at the moment go to Azure Information Explorer documentation. I’ve been assured that the precise Cloth documentation is being up to date.
Actual-Time Analytics and Azure Information Explorer use Kusto Query Language (KQL) databases and queries. Querying information in Kusto is way quicker than the transactional RDBMS, reminiscent of SQL Server, particularly when the info measurement grows to billions of rows. Kusto is known as after Jacques Cousteau, the French undersea explorer.
I used a Microsoft pattern, climate analytics, to discover KQL and Actual-Time Analytics. That pattern features a script with a number of KQL queries.
 IDG
IDGThe Cloth Actual-Time Analytics pattern gallery at the moment affords half a dozen examples, with information sizes starting from 60 MB for climate analytics to nearly 1 GB for New York taxi rides.
The KQL question for the screenshot under is attention-grabbing as a result of it makes use of geospatial capabilities and renders a scatter chart.
//We will carry out Geospatial analytics with highly effective inbuilt capabilities in KQL
//Plot storm occasions that occurred alongside the south coast
let southCoast = dynamic({"sort":"LineString","coordinates":[[-97.18505859374999,25.997549919572112],[-97.58056640625,26.96124577052697],[-97.119140625,27.955591004642553],[-94.04296874999999,29.726222319395504],[-92.98828125,29.82158272057499],[-89.18701171875,29.11377539511439],[-89.384765625,30.315987718557867],[-87.5830078125,30.221101852485987],[-86.484375,30.4297295750316],[-85.1220703125,29.6880527498568],[-84.00146484374999,30.14512718337613],[-82.6611328125,28.806173508854776],[-82.81494140625,28.033197847676377],[-82.177734375,26.52956523826758],[-80.9912109375,25.20494115356912]]});
StormEvents
| undertaking BeginLon, BeginLat, EventType
| the place geo_distance_point_to_line(BeginLon, BeginLat, southCoast) < 5000
| render scatterchart with (form=map)
//Commentary: As a result of these areas are close to the coast, many of the occasions are Marine Thunderstorm Winds
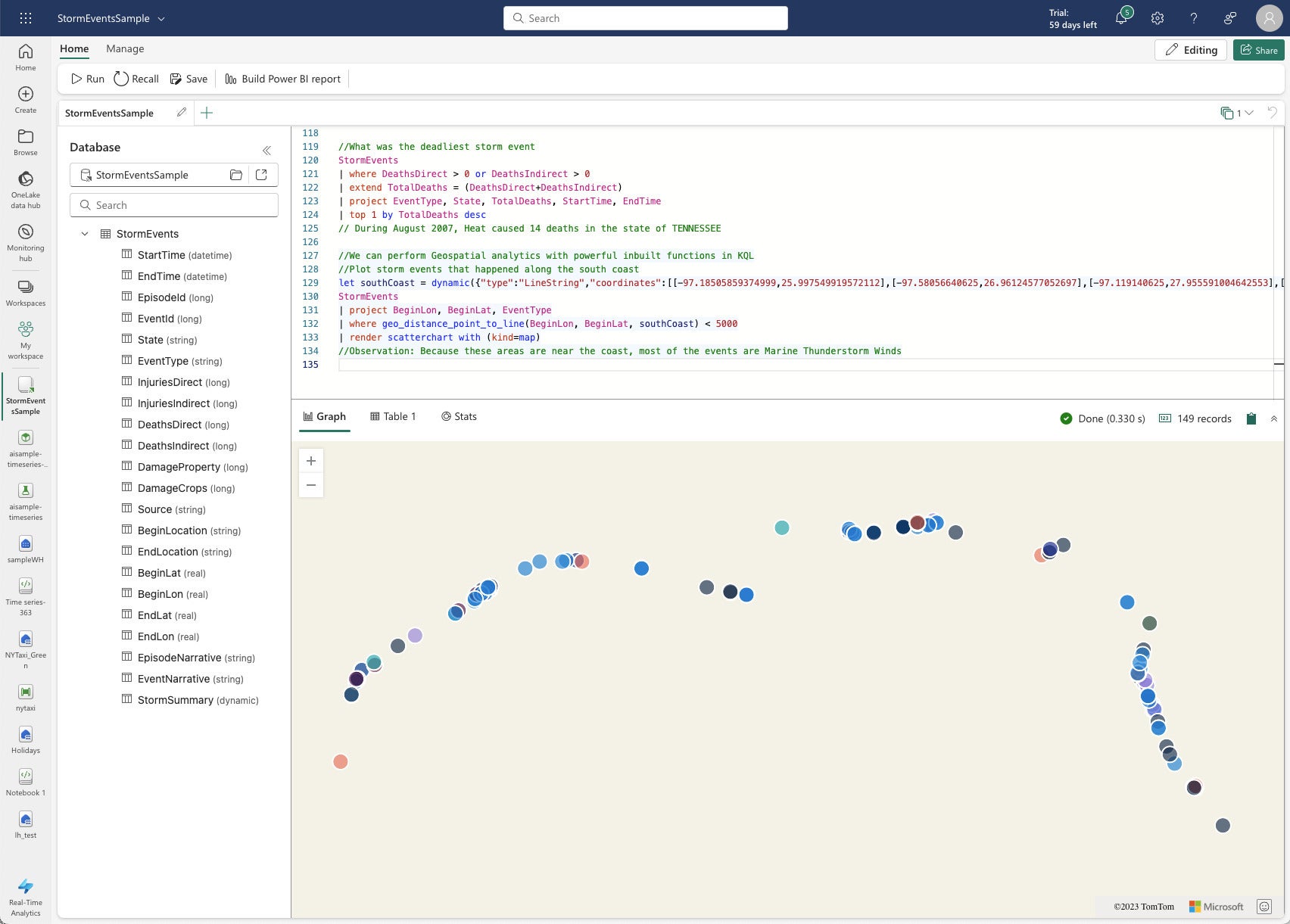 IDG
IDGRegardless of having 60 MB of knowledge, this geospatial KQL question ran in a 3rd of a second.
Broad scope and deep analytics
Whereas I found quite a few bugs whereas exploring the preview of Microsoft Cloth, I additionally acquired a good suggestion of its broad scope and deep analytic capabilities. When it’s absolutely shaken down and fleshed out, it would properly compete with Google Cloud Dataplex.
Is Microsoft Cloth actually applicable for everyone? I do not know. However I can say Cloth does a superb job of permitting you to view simply your space of present curiosity with the view switcher within the backside left nook of the interface, which jogs my memory of the best way Adobe Photoshop serves its varied audiences (photographers, retouchers, artists and so forth). Sadly, Photoshop has the well-earned repute of not solely having quite a lot of energy, however being a bear to be taught. Whether or not Cloth will develop an analogous repute stays to be seen.
Copyright © 2024 IDG Communications, Inc.

Discussion about this post